High Availability Clustering
General High Availability Concepts Understanding HA Basics
When to Use High Availability for Your Websites?

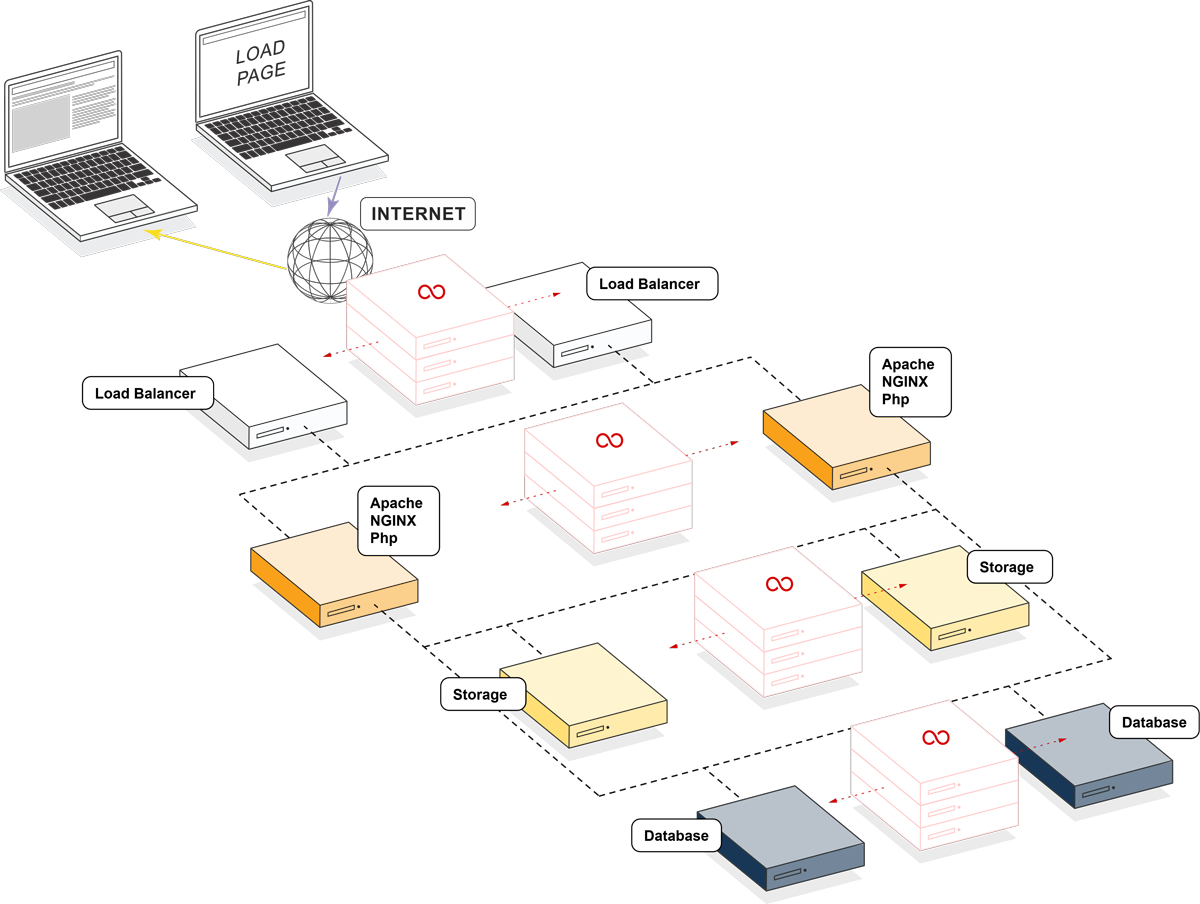
How ClusterCS Builds High Availability
Overview of Our HA Implementation
At ClusterCS, we understand that the foundation of high availability lies in robust architecture. We start by designing systems with redundancy at every level, from hardware to network configurations.
More In-Depth Considerations on How We Build the Cluster
At ClusterCS, we use a combination of synchronous and asynchronous replication methods to ensure data consistency across our nodes. Synchronous replication is used for critical data where real-time consistency is necessary, while asynchronous methods cater to scenarios where slight delays are acceptable for better performance.

Why Our Approach is Effective
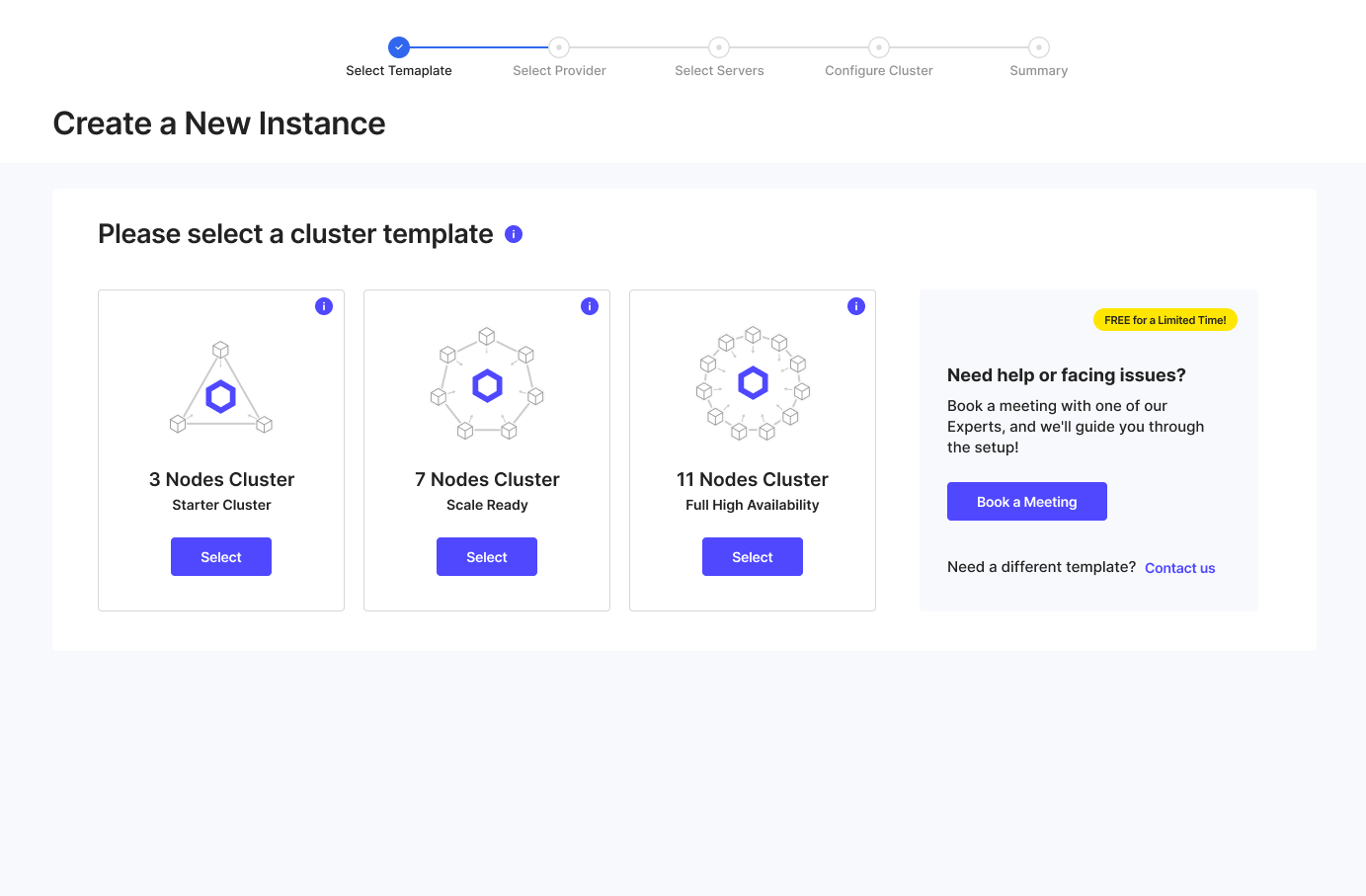
At ClusterCS, we focus on delivering high availability with simplicity and speed. Our platform enables you to start building your cluster setups in just a few clicks, thanks to our High Availability ClusterCS Templates and seamless integration with major cloud and virtualization providers.
Unlike other providers that may take weeks or even months to finalize contracts and begin the setup process, with ClusterCS, you can get started right away. No delays just immediate access to powerful infrastructure tools.
What makes us even more effective is our pricing. ClusterCS comes at just a fraction of the cost of other enterprise-grade solutions. And you still get access to key features like Managed Database Solutions, Redundant Load Balancers, and a distributed, replicated storage system.
On top of that, our Expert Support is always available. We offer custom maintenance plan design tailored to meet the needs of any client from startups to enterprises ensuring your setup is both efficient and reliable.
Our approach is designed for maximum uptime, scalability, and ease of use helping you move fast without compromising on performance or support.
Try It in Minutes
Quick Start Guide to Test ClusterCS
Setting up a new cluster with ClusterCS takes just minutes. You can easily clone your existing website and immediately begin performance benchmarking or A/B testing different server configurations—no commitments, just try our flexible hourly billing.
There’s no need to wait through lengthy onboarding processes or sign contracts to get started. Simply sign up, select your setup, and follow our intuitive guided wizard to launch your test or production environment in no time.
Need assistance? We’re here to help. Just book a meeting with our team and let’s start the conversation.